AI应用开发
岗位职责
AI Agent开发: 根据任务来自动的完成
对话系统: Chatbot(智能客服系统、问诊系统、法律咨询等)
微调: 微调垂直模型(行业模型)
训练: 多卡、分布式训练
RAG vs Fine-tuning
RAG(检索增强生成) 和 Fine-tuning(微调)
区别
- RAG: 接收到问题后,去外挂的知识库查资料, 得到检索知识后进行回答
外部知识利用
数据更新时性
可解释性
减少训练成本
- Fine-tuning: 提前学习知识,丰富自己的能力,接受问题后进行回答,得到新的大模型
任务特定优化
通用性
知识学习
资源需求: 需要大量的机器资源,包括GPU等硬件资源,训练耗时时间长
应用场景
需要及时整合动态数据: RAG
需要模型能力定制, 精准的目标检测: Fine-tuning
需要避免大模型回答的幻觉: RAG > Fine-tuning
要求回复具有可解释性: RAG
资源有限, 成本有限制: RAG
依赖模型的通用能力: RAG
要求低延迟: Fine-tuning
也可以将两者融合起来,实现优势互补
预训练的大模型
局限性
知识更新有时间差
缺失特定的领域数据(企业私有化数据)
解决方案
rag外挂知识库
fine-tuning微调
增量训练
function calling: 调用企业现有业务系统接口
专业术语
语言处理
NLP下包括NLU(理解)和NLG(文本生成)
机器学习
监督学习
监督学习(Supervised Learning)是机器学习的一种类型,它通过使用带有标签的数据集来训练模型。在这种方法中,“标签”指的是每个训练样本的正确答案或结果。
监督学习可以分为两个主要类别:
分类(Classification):当输出变量是类别或标签的时候,比如判断一封邮件是不是垃圾邮件(是/否),或者识别一张图片中的动物(猫、狗等)。分类问题的目的是将输入分配到预先定义好的类别中。
回归(Regression):当输出变量是连续值的时候,例如预测房价、股票价格或是温度等数值。回归问题旨在预测一个具体的数值输出。
监督学习的基本流程包括:
准备带有标签的训练数据。
选择一个合适的模型或算法。
使用训练数据来训练模型,即调整模型参数以最小化预测误差。
对模型进行评估,通常是在独立的测试数据集上进行,以确保模型的泛化能力,即对新数据的有效性。
如果需要,调整模型参数或特征选择,重复训练和评估过程,直到达到满意的性能水平。
无监督学习
无监督学习(Unsupervised Learning)是机器学习的一种类型,它与监督学习的主要区别在于数据的标签。在无监督学习中,算法接收的数据没有对应的标签或结果,这意味着模型必须自己去发现数据中的结构和模式。
无监督学习通常用于以下几种任务:
聚类(Clustering):将数据点分组为若干个簇,使得同一个簇内的成员比其他簇的成员更加相似。常见的聚类算法有K均值聚类(K-means)、层次聚类(Hierarchical Clustering)等。
降维(Dimensionality Reduction):减少数据集的变量数,同时尽量保持尽可能多的信息。这有助于去除噪声、简化模型,并使数据更易于可视化。常用的技术包括主成分分析(PCA)、t-分布式随机邻域嵌入(t-SNE)等。
关联规则学习(Association Rule Learning):寻找数据集中不同属性之间的有趣关系。例如,市场篮子分析可以找出哪些商品经常一起被购买。Apriori算法和Eclat算法是常用的关联规则学习方法。
密度估计(Density Estimation):估计产生观测数据的概率分布。这对于异常检测(Anomaly Detection),即识别不符合预期模式的数据点非常有用。
生成模型(Generative Models):这类模型尝试学习数据的分布以便能够生成新的类似数据样本。变分自编码器(VAE)和生成对抗网络(GANs)是两个流行的生成模型例子。
无监督学习的一个关键挑战是评估模型性能的难度,因为缺乏明确的“正确答案”。因此,评估通常是基于定性指标或是通过观察模型对新数据的行为来进行。此外,由于无监督学习试图从数据本身挖掘信息,所以它对于探索未知的数据结构和特性特别有价值,但也可能需要更多的领域知识来解释结果。
强化学习
强化学习(Reinforcement Learning, RL)是一种机器学习的类型,它关注的是如何基于环境所给予的奖励或惩罚来采取一系列行动以实现累积奖励的最大化。强化学习中的智能体(Agent)通过与环境(Environment)互动来学习最佳行为策略(Policy),即在给定状态下应该采取的最佳行动。
以下是强化学习的一些关键概念:
智能体(Agent):是学习和做出决策的部分,它根据当前状态选择动作。
环境(Environment):是智能体所在的外部世界,它可以响应智能体的动作,并提供新的状态和可能的奖励。
状态(State):表示环境的一种情况或配置,智能体根据当前的状态来决定其下一个动作。
动作(Action):是智能体可以执行的操作,这些操作会改变环境的状态。
奖励(Reward):是在特定状态下执行特定动作后,环境对智能体的反馈。奖励可以是正数(鼓励)或负数(惩罚)。
策略(Policy):定义了在给定状态下智能体应采取什么动作。这是智能体的核心,也是需要学习的东西。
价值函数(Value Function):评估某个状态或状态-动作对的好坏,通常用以预测从该状态开始遵循某种策略可以获得的长期奖励。
深度学习
Deep Learning
一种机器学习架构, 使用多层人工神经网络,模仿人脑的工作方式来解决复杂的模式识别问题。能够从图像,语音、自然语言中自动提取高层次的特征。
Transformer
完全基于自注意力机制(self-attention)来处理输入序列的依赖关系,摒弃了循环和卷积操作。
从片段记忆到全局记忆,从串行处理到高效并行
GPT的T就是指Transformer
AIGC
生成式AI
AI Generated Content
大模型下载
向量模型的选择依据是什么? 对模型自行进行评估,自己测试效果
文本生成模型
中文为主的大模型
选择多大尺寸的模型?
7B 大部分企业选择
3B 24G以上的显卡推理
小技巧
查看显卡命令: nvidia-smi
RAG开发
检索(Retrieval)增强(Augmented)生成(Generation)
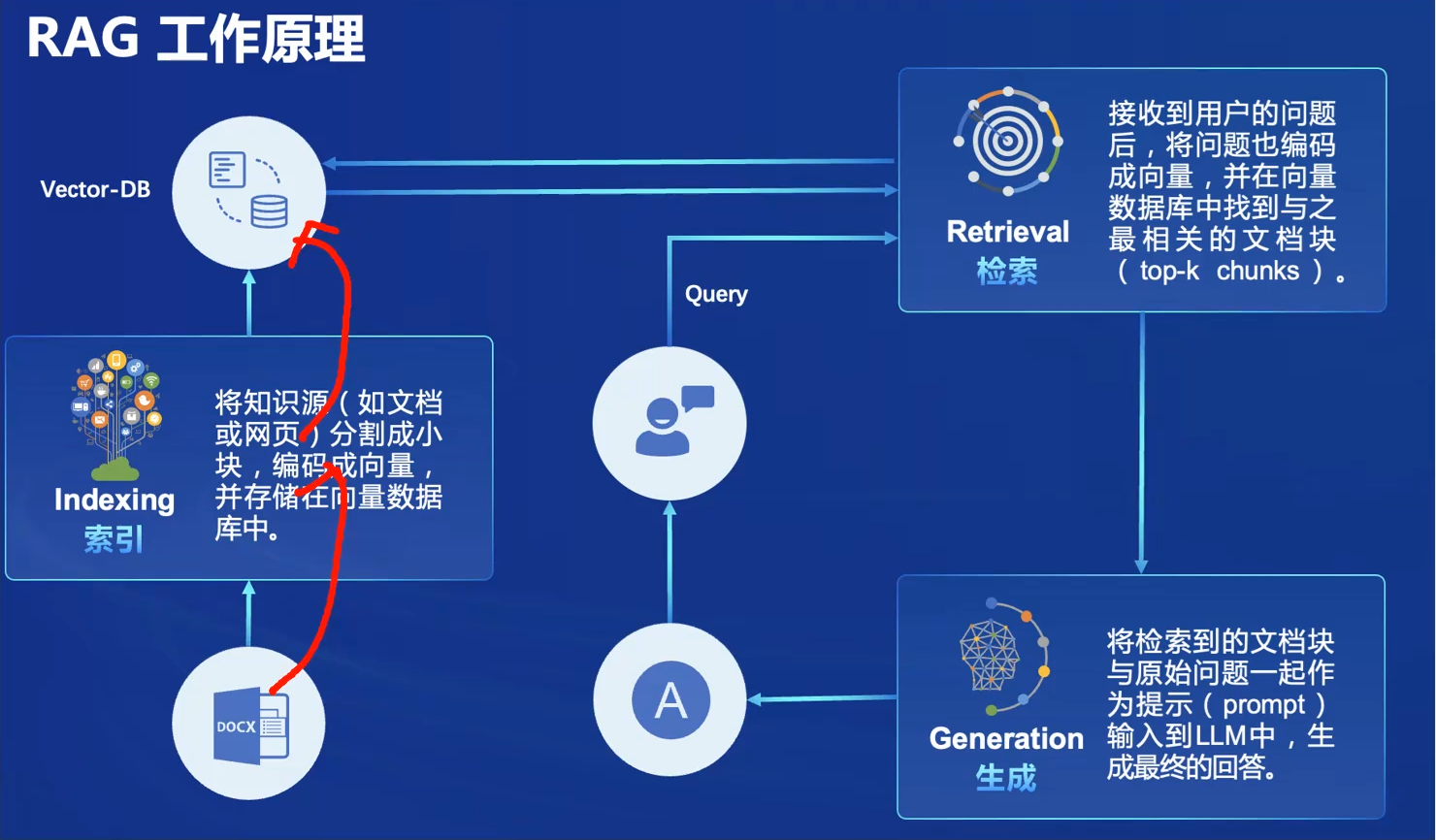
开发流程
离线步骤
文档加载
文档切分
向量化
在线步骤
获得用户问题
用户问题向量化
检索向量数据库
将检索结果和用户问题填入Prompt模板
用最终获得的Prompt调用LLM
由LLM生成回复
用了一个开源的RAG, 不好使怎么办?
检查预处理效果: 文档加载是否正确,切割的是否合理
测试检索效果: 问题检索回来的文本片段是否包含答案
测试大模型能力: 给定问题和包含答案文本片段的前提下, 大模型能不能正确回答问题
大模型微调
利用gitee实现大模型微调, 降低训练成本: https://ai.gitee.com/docs/training